Abstract
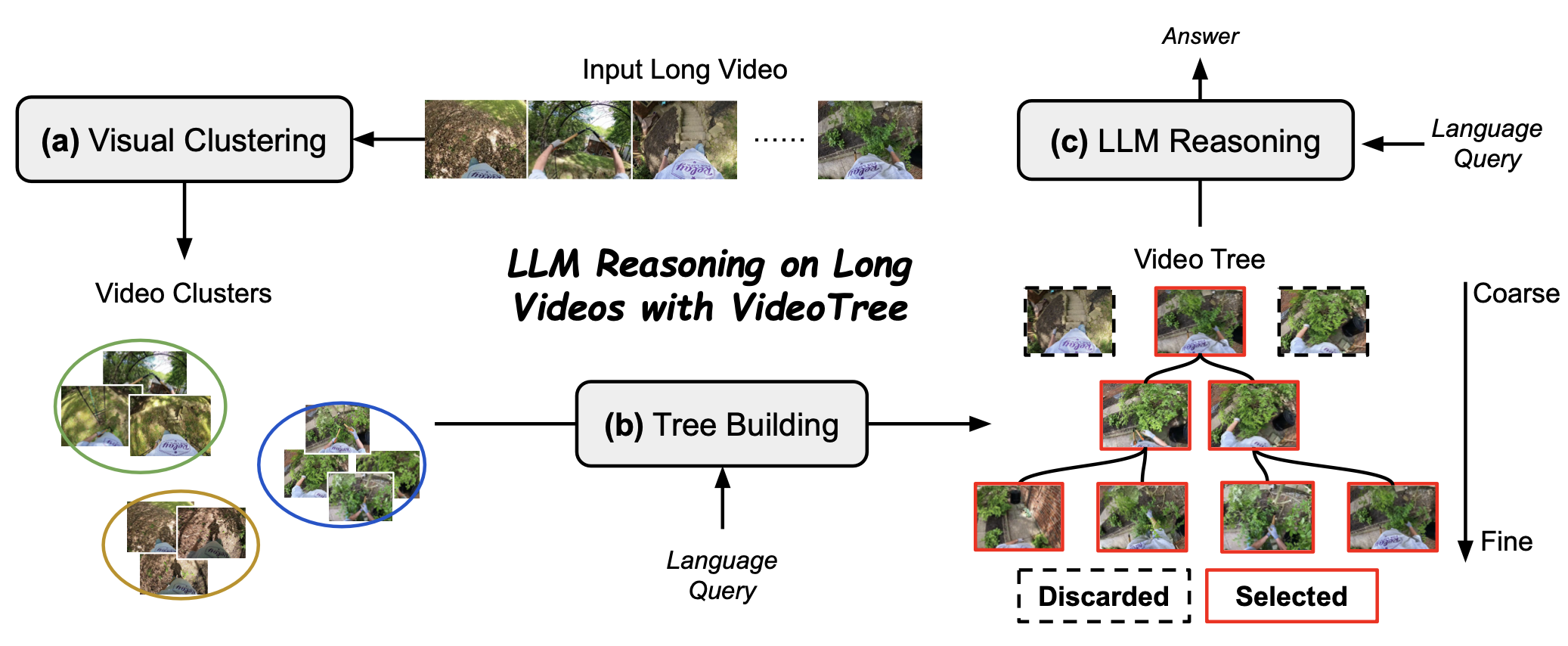
Video-language understanding tasks have historically focused on short video clips, often struggling with the complexities of long-form video understanding. Recently, many long video-language understanding approaches have taken advantage of the reasoning capabilities of Large Language Models (LLMs) to perform long video question answering, transforming videos into densely sampled frame captions, and asking LLMs to respond to text queries over captions. However, the frames used for captioning are often redundant and contain irrelevant information, making dense sampling inefficient, and ignoring the fact that video question-answering requires varying levels of granularity, with some video segments being highly relevant to the question (and hence needing more fine-grained detail) while others being less relevant. Thus, these LLM-based approaches are prone to missing information and operate on large numbers of irrelevant captions, lowering both performance and efficiency. To address these shortcomings, we introduce VideoTree, a query-adaptive and hierarchical framework for long-video understanding with LLMs. Specifically, VideoTree dynamically extracts query-related information from the input video and builds a tree-based video representation for LLM reasoning. First, VideoTree adaptively selects frames for captioning by clustering frames based on their visual features and scoring clusters based on their relevance to the query. We iterate this process until enough query-related keyframes are extracted. Second, it organizes visual clusters into a query-adaptive and hierarchical tree structure; the structure of the tree encodes varying levels of granularity, with higher (deeper) resolution on relevant segments. Finally, VideoTree produces an answer to each question by traversing the tree’s keyframes and passing their captions to an LLM answering model, which answers the query. Our experiments show that our training- free adaptive method improves both reasoning accuracy and efficiency compared to existing methods: VideoTree achieves a 7.0%, 2.2%, and 2.7% improvement in accuracy over existing methods on the popular EgoSchema, NExT-QA, and IntentQA benchmarks, respectively, while reducing inference time by 40%.
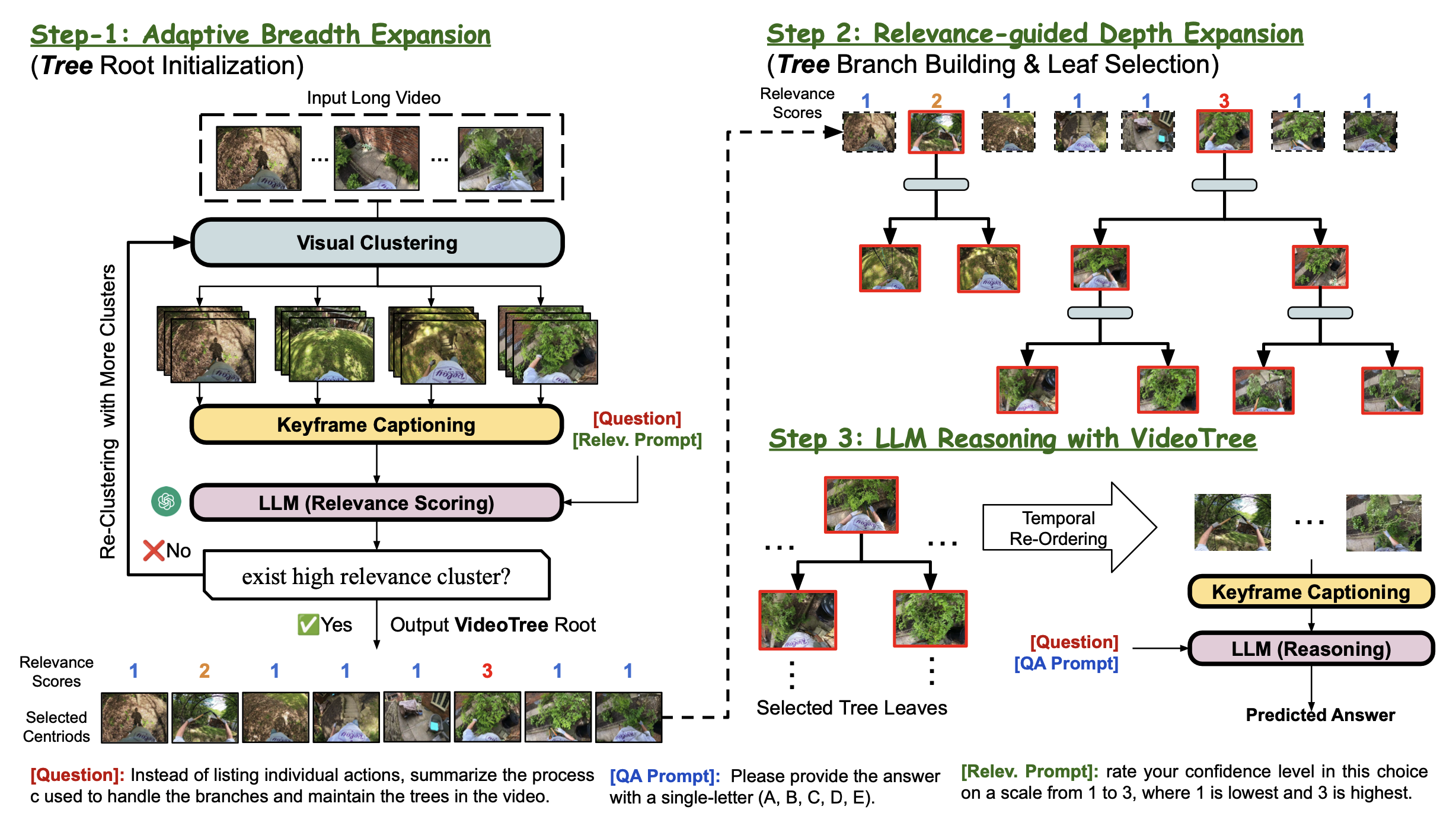
Method
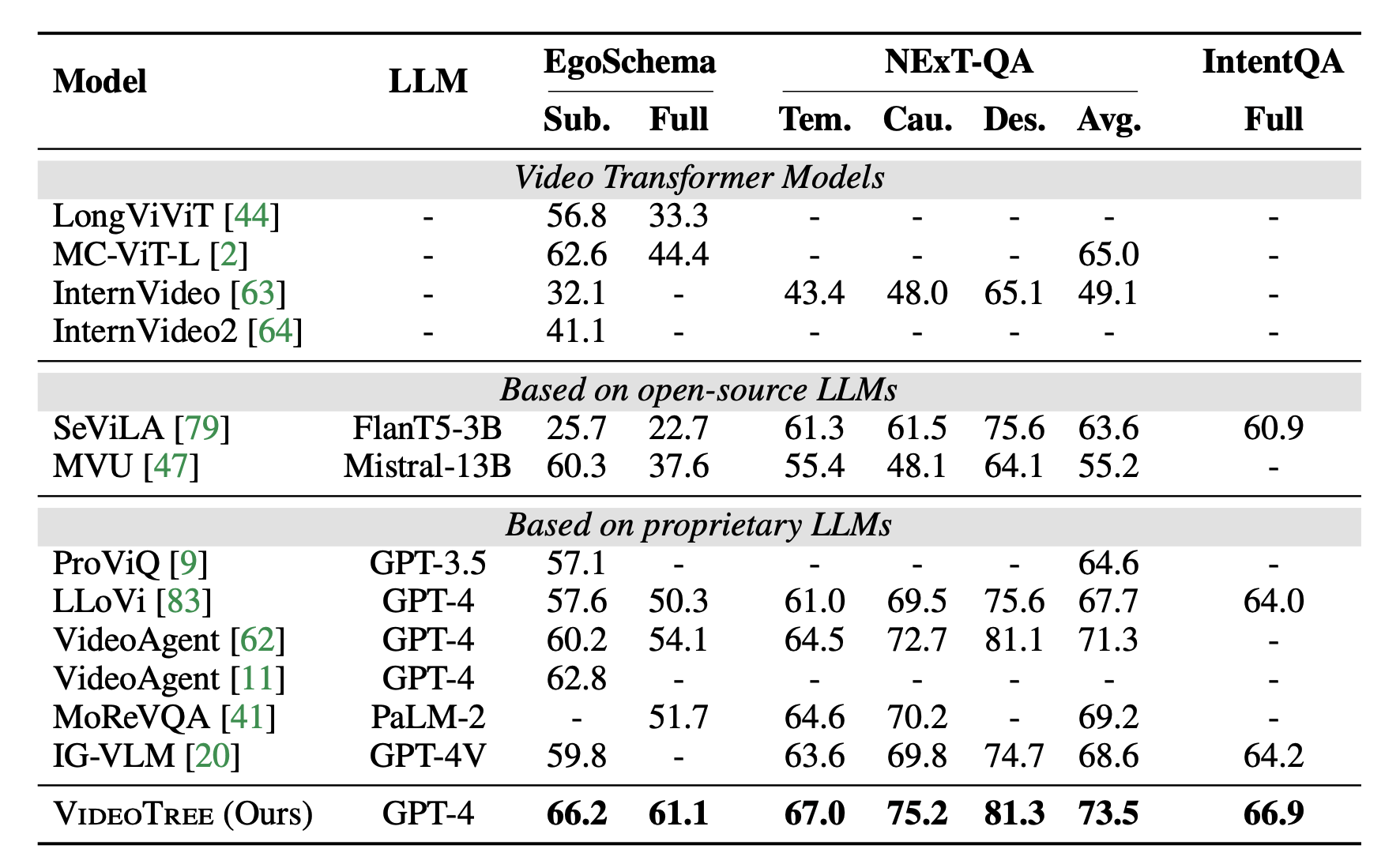
Results
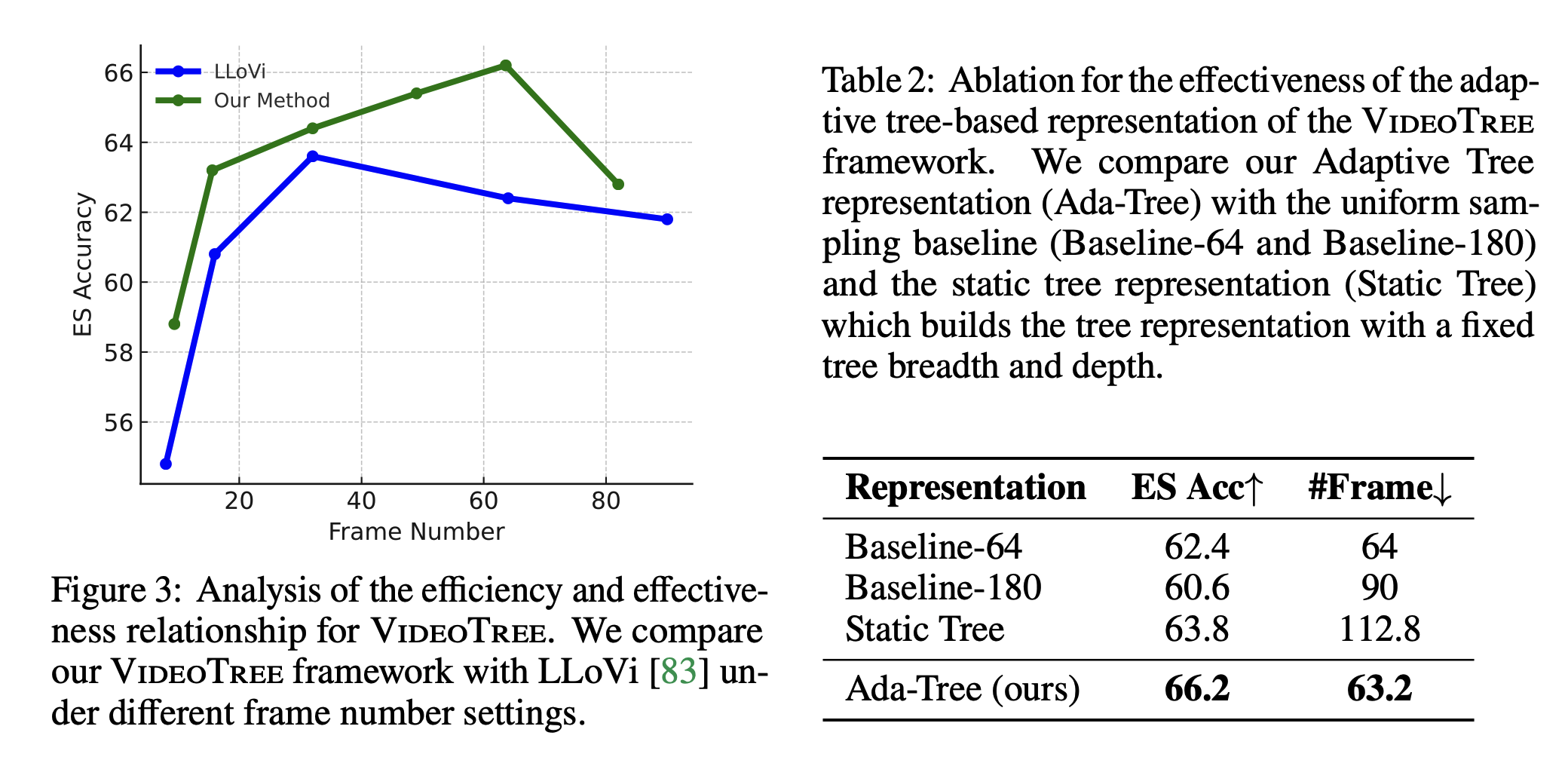
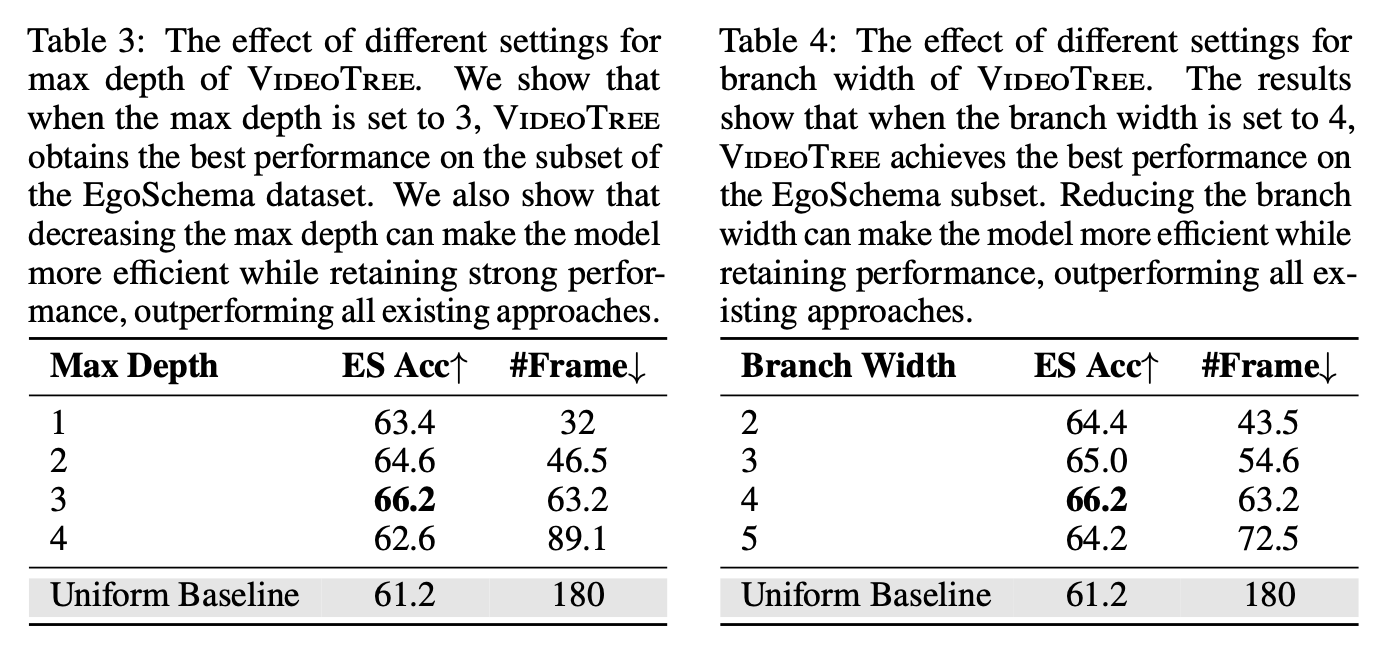
Abalation Study
Qualitative Analysis

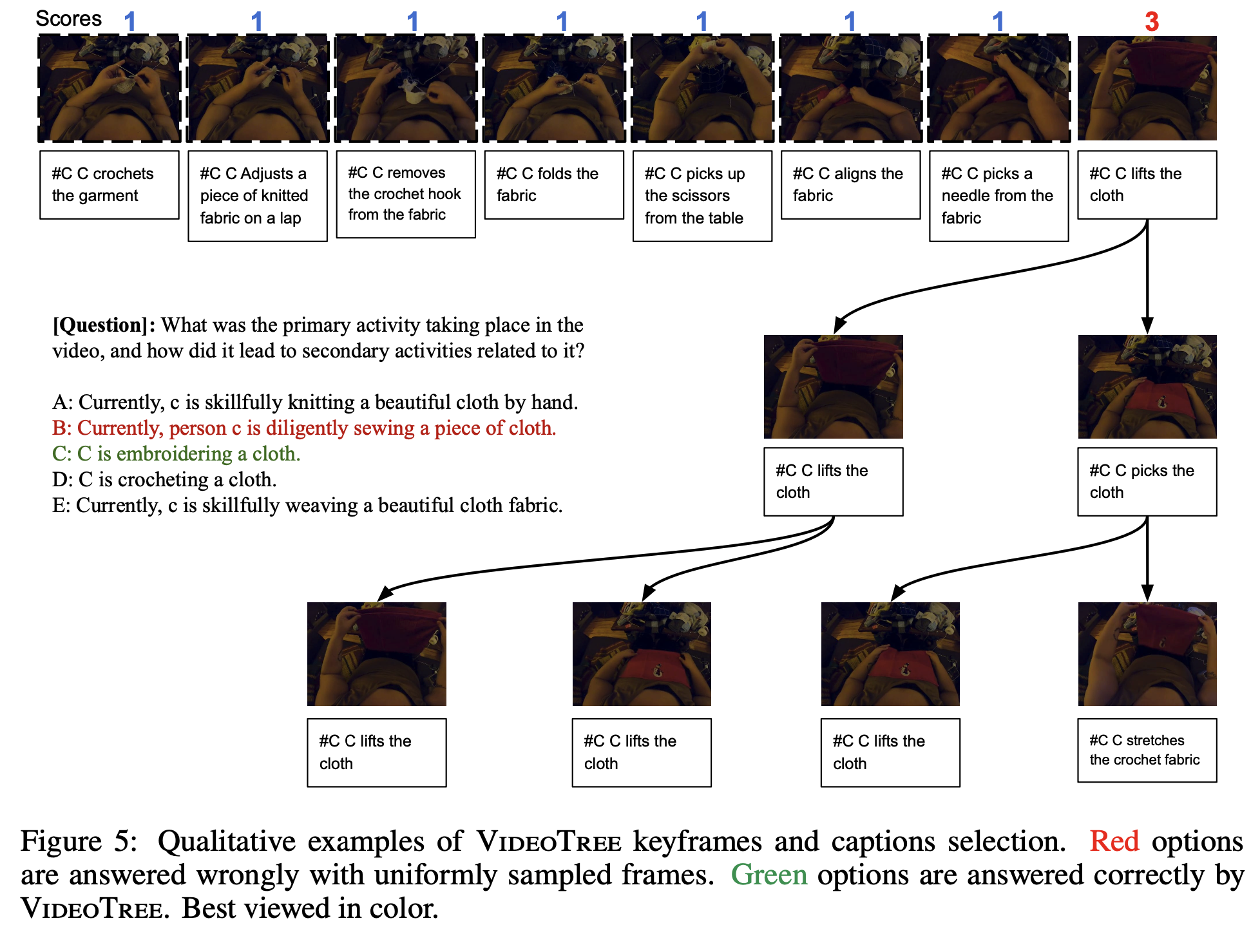
We visualize qualitative results from VideoTree. Specifically, we show the keyframes and their captions extracted by our adaptive tree representation given a video query. This example is drawn from EgoSchema, and shows the query format, which consists of a query and multiple choice answers. With the proposed VideoTree strategy, we can split a complex multi-scene video (e.g.cleaning house across rooms) into several key scenes via visual clustering and determine the most query-relevant scene via the relevance score. We then can obtain more fine-grained visual cues by descending into each relevant cluster (Levels 2 and 3 in Figure 5 top). For example “C opens a washing machine” is deemed highly relevant to the question, which asks about the sequence of events. At the same time, frames like “C moves around” are deemed irrelevant to the query and not expanded. In the end, VideoTree shows a dynamic ability to select relevant segments and can answer the given question correctly with only 50% of the baseline’s 32 input captions. The baseline (fixed uniformly sampling) fails to correctly answer the question, sampling a large number of redundant and irrelevant frames.
BibTeX
@article{wang2024videotree,
author = {Ziyang Wang, Shoubin Yu, Elias Stengel-Eskin, Jaehong Yoon, Feng Cheng, Gedas Bertasius, Mohit Bansal},
title = {VideoTree: Adaptive Tree-based Video Representation for LLM Reasoning on Long Videos},
journal = {arxiv},
year = {2024},
}